2025-09-14: GKE Auto-Upgrade Failure
Root cause analysis for GKE cluster auto-upgrade failure on September 14, 2025
Incident Summary
Date & Time
- Date: September 14, 2025
- Duration: 15 hours
- Severity: Critical
What Happened
Despite having auto-upgrade disabled on node pools, Google forced a control plane upgrade from v1.32.x to v1.33.2 due to version deprecation deadline. Existing nodes continued running, but any new nodes failed to initialize properly in both v1.32 and v1.33 versions. This critically impacted spot instances which frequently cycle - when spot nodes were preempted and recreated, they couldn’t rejoin the cluster, causing progressive service degradation.
Impact Assessment
Services Affected
- Partially Working: API endpoints (running on existing nodes only - no autoscaling possible)
- Completely Down:
- Background workers (running on spot instances)
- Reporting services
- Order allocation systems
- Any workload requiring new nodes (both spot and standard instances affected)
Business Impact
- APIs remained functional but couldn’t scale to handle load spikes
- Background job processing completely stopped
- Report generation failed
- Order allocation and fulfillment halted
- Progressive degradation as any node autoscaling failed
Root Cause Analysis
Primary Causes
- Forced Control Plane Upgrade: Google forced upgrade despite auto-upgrade being disabled due to version deprecation deadline
- Node Initialization Corruption: ALL new nodes failed (both spot and standard) - only existing nodes continued running
- Complete Autoscaling Failure: No new nodes could join the cluster, preventing any scaling
- NodeLocalDNS Initialization Failure: DNS pods stuck in crash loops on all new nodes
- Network Plugin (netd) Failures: Network plugin couldn’t initialize, preventing pod networking
- CSI Driver Mount Issues: Persistent volume mounting failed due to CSI driver initialization problems
- ConfigMap Mount Failures: Critical system ConfigMaps failed to mount on new nodes
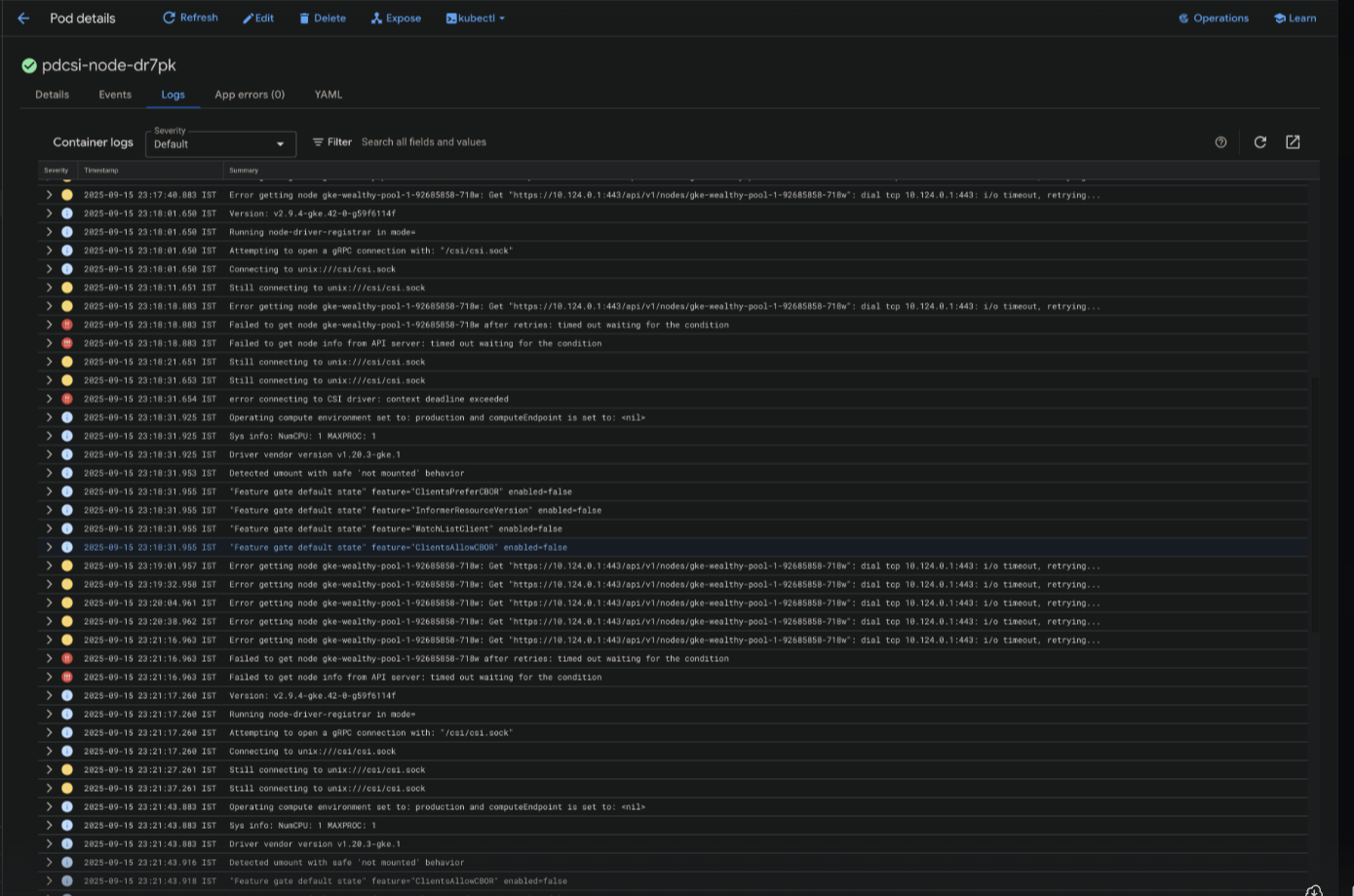 Screenshot showing multiple system pod failures including NodeLocalDNS crashes, CSI driver timeouts, and API server connection errors
Screenshot showing multiple system pod failures including NodeLocalDNS crashes, CSI driver timeouts, and API server connection errors
Sample Error Logs
CSI Driver Registration Failure:
I0914 07:11:29.647586 1 main.go:135] Version: v2.9.4-gke.42-0-g59f6114f
I0914 07:11:29.647948 1 main.go:136] Running node-driver-registrar in mode=
I0914 07:11:29.647953 1 main.go:157] Attempting to open a gRPC connection with: "/csi/csi.sock"
I0914 07:11:29.647962 1 connection.go:214] Connecting to unix:///csi/csi.sock
W0914 07:11:39.648572 1 connection.go:233] Still connecting to unix:///csi/csi.sock
W0914 07:11:49.648678 1 connection.go:233] Still connecting to unix:///csi/csi.sock
W0914 07:11:59.648959 1 connection.go:233] Still connecting to unix:///csi/csi.sock
E0914 07:11:59.648981 1 main.go:160] error connecting to CSI driver: context deadline exceeded
Secondary Issues (Discovered During Recovery)
- Istio Compatibility: Kubernetes 1.33 required Istio upgrade to 1.27.1. See helm repo.
- Cert-Manager Updates: Required updates for Kubernetes 1.33 compatibility (see {helm-repo}/prod/cert-manager/gke-v2)
Contributing Factors
- Running on Kubernetes version approaching GKE deadlines
- Heavy reliance on spot instances for critical background workers (cost benefits)
- No standby/failover cluster in GCP (dev cluster on different cloud provider)
- No rollback possible once node initialization was corrupted
Resolution Steps
Immediate Actions (Attempts to Recover)
- Attempted to restart failed pods and nodes - no success
- Tried rolling back node versions - new nodes still wouldn’t initialize
- Attempted to disable/re-enable NodeLocalDNS addon:
1# Disabled NodeLocalDNS (succeeded but slowed DNS resolution) 2gcloud container clusters update wealthy --update-addons=NodeLocalDNS=DISABLED 3 4# Attempted to re-enable NodeLocalDNS (failed) 5gcloud container clusters update wealthy --update-addons=NodeLocalDNS=ENABLED 6# Error: INVALID_ARGUMENT: Node pool "t2d-64gb-standard" requires recreation - Attempted node pool recreation - failed with same initialization issues
- Conclusion: Cluster corruption was irreversible
Final Resolution (New Cluster Creation)
- Created new GKE cluster at v1.33 (same version as forced upgrade)
- Updated Istio to 1.27.1 for compatibility
- Updated cert-manager configurations (helm/prod/cert-manager/gke-v2)
- Migrated all production workloads to new cluster
- Verified all services operational
- Decommissioned corrupted cluster
Validation
- Verified all pods scheduling correctly
- Confirmed DNS resolution working
- Tested PVC mounting functionality
- Validated external integrations
Prevention Measures
- Stable Channel Strategy: Keep all clusters on GKE stable release channel for predictable updates
- Management Cluster Architecture: Separate cluster for management plane running Argo CD, monitoring, and other control plane components
- Staged Upgrade Process:
- SRE updates management cluster first when new stable releases are available
- Monitor for several days before updating production clusters
- Test upgrades in management cluster before production rollout
- Version Pinning: Explicitly manage Istio, cert-manager, CSI, and DNS addon versions
- Compatibility Matrix: Maintain Kubernetes-Istio-cert-manager compatibility matrix per Istio supported releases
- Proactive Upgrades: Stay current with stable releases to avoid approaching deprecation deadlines
- Monitor GKE Alerts: Regularly check GKE alerts and announcements on Google’s dashboard for potential upcoming issues
Lessons Learned
Key Takeaways
- Google forces control plane upgrades at version deprecation deadlines even with auto-upgrade disabled
- Stay within supported version window to avoid forced upgrades
- Existing nodes can remain functional while new node initialization fails completely
- Spot instances create cascading failures when nodes can’t rejoin after preemption
- Control plane upgrades can cause irreversible node initialization corruption requiring full cluster recreation
- Use GKE stable channel for predictable and tested release cycles
- Kubernetes upgrades require careful coordination of all dependent components (Istio, cert-manager)
- No standby cluster in same cloud provider creates recovery risks with no immediate failover option
- SRE-managed staged rollouts reduce upgrade risks
Action Items
- Configure all clusters to use GKE stable release channel
- Implement management cluster (Q4 2025)
- Review spot instance usage for critical workloads - add on-demand fallback pools
- Document SRE upgrade procedure: management cluster first, then production after monitoring period
- Document Kubernetes-Istio-cert-manager compatibility matrix
- Create automated upgrade testing pipeline
- Reserve static IPS for quick migrations
- Implement version pinning strategy for Istio and cert-manager and other if not there.